The web feels different now, and you can feel it fast. A blog post, student essay, product review, or support article can look completely normal while still being AI-written. That is why AI detection tools keep popping up in schools, publishing, SEO, and trust-heavy platforms. Turnitin, GPTZero, Copyleaks, and Originality.ai all now sell detection tools for exactly that reason.
But this is where it gets messy. AI detection is useful, yet it is nowhere near perfect. OpenAI shut down its own AI writing classifier because of low accuracy, and it has also warned that detectors can falsely label human writing, including work by English learners and even famous human-written texts.
So the real question is not just, “Which detector exists?” It is: Which tool is good enough for your use case, how should you use it, and how do you avoid accusing real people unfairly? That is what this guide gets into: how AI detection APIs work, which ones stand out, and where teams usually get burned.
The science behind AI content detection
It sounds a bit magical at first, but AI detection is really a pattern-matching problem. Unlike plagiarism checkers, which look for copied text, AI detectors try to spot statistical signals in the writing itself. OpenAI’s own past writing-classifier work described this as a supervised classifier trained on human-written and AI-written responses to the same prompts, not a web search for duplicates. It also warned that this kind of detection is limited and can be wrong.
Two ideas come up a lot in public discussions of detection tools:
- Perplexity. This is basically a measure of how predictable the text is. AI-generated writing often follows more statistically likely word patterns, so it can look smoother and more expected. Human writing tends to be messier. People use odd phrasing, jump in tone, throw in fragments, or pick words a model might not rank first.
- Burstiness. This is about variation. AI text often has a more even rhythm: similar sentence lengths, similar paragraph shape, similar pacing. Human writing usually has more swing. A long sentence. Then a short one. Then something abrupt. GPTZero is one of the better-known tools that publicly talks about perplexity and burstiness as part of its detection framing.
So when a detector scans a document, it is usually not asking, “Did this exact paragraph come from ChatGPT?” It is asking something more like:
- How predictable is this text?
- How even is the sentence structure?
- Does the rhythm look too uniform?
- Does the wording match patterns common in model output?
If enough of those signals line up, the tool may flag the text as likely synthetic.
That said, this is where readers need a reality check. These signals are useful, but they are not proof. OpenAI said its own classifier was unreliable, especially on short text, non-English text, and text that had been edited. It also noted false positives on human writing.
Why businesses add AI detection APIs
There is a reason more platforms keep adding AI detection. Once synthetic text starts to mix into essays, listings, reviews, applications, or publisher submissions, trust gets harder to maintain.
To protect quality, especially in search-heavy platforms
Google does not ban AI content just because AI helped write it. The problem is large-scale, low-value content made mainly to manipulate rankings. Google’s spam policies call this scaled content abuse. So if your platform depends on user submissions or indexed pages, detection can help you catch low-effort synthetic spam before it drags quality down.
To protect academic and professional integrity
This is one of the biggest use cases. Schools, hiring platforms, and assessment tools use detection to spot work that may not reflect the writer’s actual effort or skill. Turnitin openly positions AI detection around academic integrity and original work, which tells you how central this has become in education.
To reduce copyright risk
This part is easy to get wrong, so here is the careful version: you cannot assume fully AI-generated text is protected by copyright in the same way as human-authored work. The U.S. Copyright Office says copyright protection depends on human authorship, and AI outputs can be protected only where a human contributed enough original expressive control, arrangement, or modification.
So for publishers, detection can help flag content that may need closer review before it is treated as owned editorial IP.
To triage huge content volume faster
Nobody wants editors or reviewers reading thousands of submissions by hand just to find the risky ones. Detection APIs help by scoring content first, so teams can route likely synthetic text into a review queue instead of manually checking everything.
That does not make the detector the final judge, but it does make the workflow much faster. Turnitin’s current model even breaks detected text into categories such as likely AI-generated and likely AI-generated then AI-paraphrased, which shows how these tools are now being used as triage layers, not just yes-or-no alarms.
The top 5 AI detection APIs in 2026
Based on current product claims, feature depth, and how these tools are being positioned in education, publishing, and enterprise workflows, these five are the names that come up most often. One quick reality check, though: the AI detection market is full of huge accuracy claims, and those numbers are usually based on vendor or partner testing, not a single universal benchmark. So it makes more sense to compare these tools by use case, false-positive risk, language support, and API depth than by one headline percentage alone.
Copyleaks
Copyleaks is one of the most established enterprise options in this space. It is built for schools, publishers, and larger organizations that want AI detection, plagiarism checks, and governance controls in one system. Copyleaks says it supports 30+ languages for AI detection, can detect AI-generated source code, and offers API access for enterprise and education customers. It also advertises over 99% accuracy and a very low false-positive rate, though those figures come from its own testing and referenced third-party studies.
Key features:
- AI text detection
- AI-generated source code detection
- Plagiarism detection
- 30+ language support for AI detection
- API access and enterprise controls
- Compliance and governance positioning
Pricing: Personal plans start at $16.99/month, while API and enterprise pricing are handled separately through sales.
Best for: Enterprises, publishers, and education platforms that want a more complete integrity stack, not just a standalone checker.
| Pros | Cons |
| Strong enterprise and education fit | API pricing is not simple or public for bigger use cases |
| Broad language support | Premium tiers get expensive fast |
| Covers code as well as text | Strict detection can still create disputes on edited text |
| Strong governance and API tooling |
GPTZero
GPTZero still has one of the strongest positions in education-focused AI detection. Its product is built around schools, student writing, and “prove your work” workflows, which makes it feel more transparent than tools that only return a score. GPTZero says it detects GPT-5, Gemini, and other major models, and it also promotes low false-positive rates plus writing-process features such as document history and replay-style tooling.
Key features:
- AI text detection
- Sentence-level highlighting
- Writing-process and originality workflow tools
- Education and LMS focus
- API access
- Model coverage for major current LLMs
Pricing: API plans scale based on word count (e.g., 1M words for $135/month).
Best for: EdTech, universities, assessment products, and any workflow where false accusations would be especially painful.
| Pros | Cons |
| Strong education fit | More text-focused than broad multimodal platforms |
| Transparent scoring and workflow tools | Heavily edited hybrid text can still be tricky |
| Public emphasis on low false positives | Pricing is less straightforward from public pages |
| Good API story for institutional use |
Pangram
Pangram is a more specialized detector. It is less of a “content suite” and more of a focused AI detection product. The company pushes very hard on near-zero false positives, multilingual support, and research-heavy credibility, including references to third-party reviews and university-linked evaluations. It also emphasizes API integration for high-volume use cases.
Key features:
- AI text detection
- 20+ language support
- API access
- Detailed probability-style responses
- Emphasis on low false positives
- Detection of “AI-assisted” and humanized text
Pricing: Enterprise API pricing (starts around $15/month for basic web access, custom for heavy API use).
Best for: Institutions and organizations that care a lot about minimizing false accusations and want a more detection-first product rather than a giant bundle of writing tools.
| Pros | Cons |
| Strong false-positive positioning | Smaller ecosystem than Copyleaks or GPTZero |
| Good multilingual support | Less of an all-in-one integrity suite |
| API-ready for higher-volume use | Public pricing is limited |
| Clear detection-first focus |
Winston AI
Winston AI is aimed more at publishers, agencies, and web content teams. It goes beyond plain text detection and adds plagiarism, readability, image detection, and OCR-based document or handwriting scanning. That wider feature mix is a big part of its pitch. Winston also publicly lists monthly pricing and per-credit usage rules, which makes it easier to size up than some enterprise-only tools.
Key features:
- AI text detection
- AI image and deepfake detection
- OCR for documents and handwriting
- Plagiarism detection
- Readability and writing feedback
- HUMN-1 certification features
Pricing: Starts at $12/month for basic limits; API access requires custom scaling.
Best for: Publishers, SEO teams, agencies, and platforms that want more than pure text detection.
| Pros | Cons |
| Broader feature set than many rivals | Broad toolset can mean less focus on one core use case |
| Includes image detection and OCR | Accuracy claims are still vendor-reported |
| Clearer public pricing | Complex or hybrid text may still create aggressive scores |
| Good fit for content teams |
Originality.ai
Originality.ai is probably the strictest content-market and SEO-facing option in this group. Its site leans hard into publisher workflows, site-wide scanning, fact checking, readability, and zero-tolerance or lower-tolerance models for AI-assisted content. It also offers different detection models depending on whether you allow light AI editing or want a much stricter standard. That flexibility is a big part of why it appeals to agencies and publishers.
Key features:
- AI text detection
- Plagiarism checking
- Readability tools
- Fact-checking tools
- Bulk and site-wide scanning
- Different detector models for different AI policies
- API access and team controls
Pricing: Pay-as-you-go credits (e.g., $30 for 300,000 words).
Best for: SEO agencies, content marketplaces, publishers, and managers who want stricter control over AI use in submitted content.
| Pros | Cons |
| Strong fit for SEO and publishing workflows | Can feel too strict for some educational or mixed-use settings |
| Includes fact-checking and readability tools | Strict models can create more disputes if policy is unclear |
| Offers different detector models by use case | Credit model may be less intuitive for casual users |
| Useful for site-wide content QA |
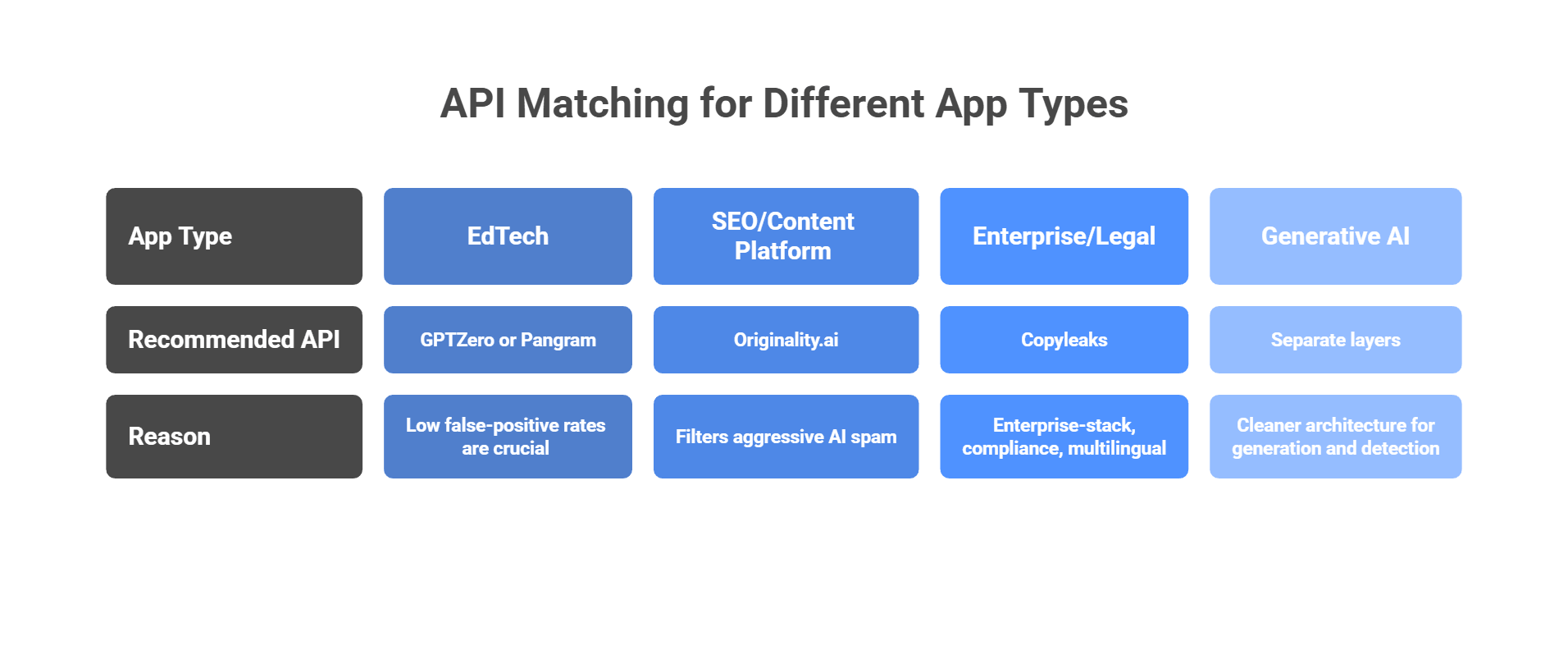
Decision matrix: Matching the API to your app
This part really comes down to one question: what hurts more in your product: missing AI text, or falsely accusing a real person? That is the tradeoff behind almost every detection choice. Some tools lean hard toward stricter catching. Others put more weight on protecting human writers from false flags.
If you are building an EdTech app
Look first at GPTZero or Pangram. In education, a false positive is a big deal. GPTZero is built heavily around schools, writing-process review, and sentence-level analysis, while Pangram puts a huge amount of its messaging around low false-positive rates and student-writing use cases. That makes both a better fit when you need to be careful with accusations.
If you are building an SEO or content platform
Originality.ai makes the most sense when your main problem is cheap AI spam, scaled content, or low-trust submissions. Its product is aimed squarely at publishers, SEO teams, website scanning, and content quality workflows. In that kind of environment, a stricter detector can actually be useful, because your goal is to filter aggressively before weak content spreads across the site.
If you are building an enterprise or legal workflow
Start with Copyleaks. It is the most “enterprise-stack” option in this group: strong compliance positioning, multilingual AI detection, code-related detection, and a broader authenticity platform around plagiarism and governance. That is the kind of setup that fits large organizations handling policy-heavy, multilingual, or code-adjacent content.
If you are building a full-stack generative AI app
Keep your generation layer and your detection layer separate. That is the cleaner architecture. Generate with the models you want, then send finished content through a detection API as a separate review step.
If you are juggling several LLM providers for generation, a unified gateway can simplify the generation side by reducing provider sprawl and key management, while your detection service stays independent and stable. That separation matters because detection and generation solve different problems and should not be tightly coupled in one brittle workflow. This last point is more of an engineering recommendation than a vendor-verified product claim.
The Reddit reality check: False positives and evasion
This is the part people usually learn the hard way. AI detection sounds neat in product demos, but once real users get involved, things get messy fast. Spend five minutes in communities like r/AskProfessors and you will see the same pattern: false flags, policy confusion, and a lot of anger when a score gets treated like proof. Stanford researchers have also warned that detectors are not especially reliable and can be unfair to some groups, especially non-native English writers.
The issue: Bias against non-native English speakers
This is one of the biggest problems. Stanford researchers found that AI detectors were much more likely to misclassify writing from non-native English speakers as AI-generated. The basic reason is not mysterious: more structured, careful, less idiomatic writing can look “too predictable” to a detector. OpenAI has also publicly warned that provenance and detection methods can unfairly affect non-native English speakers.
The fix: Do not treat a detector score as final proof. Use it as a risk signal, then look at other evidence:
- document history
- drafts or revision logs
- writing samples from the same user
- a short follow-up conversation
- version history in tools like Google Docs or Word
That is the safer move if you care about trust. Reddit threads from professors and students keep coming back to this exact point: the score alone is not enough.
The issue: The hybrid gray area
This one frustrates people a lot because it feels unfair. A student writes the draft, then uses Grammarly to smooth it out. A job applicant writes their own cover letter, then asks ChatGPT for an outline. A marketer drafts a post, then uses AI to tighten the wording. Many detectors still flag that kind of mixed workflow, even though the human did a real chunk of the work. Reddit discussions around academic use show how blurry this gets once AI moves from “write it for me” to “help me polish it.”
The fix: Set your policy before you set your threshold. Decide questions like:
- Is AI outlining allowed?
- Is grammar cleanup allowed?
- Is paraphrasing allowed?
- At what point does assistance become authorship?
If your platform has no clear answer there, the detector will create more arguments than value. A tool cannot define fairness for you. It can only score patterns.
The issue: Easy evasion
Yes, people actively try to get around detectors. Humanizer tools, paraphrasers, and heavy manual edits can make synthetic text harder to catch. Even OpenAI said its own old classifier struggled on edited text and was not reliable enough to keep online. So anyone selling detection as a magic lie detector is overselling it.
The fix: Use vendors that actively maintain and retrain their models, and assume evasion is part of the game. Copyleaks, for example, says it detects paraphrased AI content and keeps coverage current as new models appear. That does not make evasion impossible, but it is still better than relying on a static checker that has not evolved with the tools people use to bypass detection.
Want a cleaner AI stack for both detection and generation?
AI content detection can help protect quality, trust, and authenticity on your platform. But detection is only one side of the equation. If your product also depends on generative AI features, the infrastructure behind them matters just as much.
That is where LLM API fits in well. It gives you one OpenAI-compatible API, multi-provider access, performance monitoring, secure key management, cost-aware analytics, and model/provider-level usage breakdowns in one place. That can make the generative side of your product much easier to manage as it grows.
Why use LLM API for generative features?
- One API across multiple providers
- OpenAI-compatible setup for easier integration
- Cost-aware analytics to track usage and spend
- Performance and reliability monitoring in one layer
- Secure key management for cleaner team workflows
If you want to keep your platform focused on secure, authentic user experiences without making the backend harder to manage, LLM API is a natural layer to add. It helps simplify the generative side of your stack while giving you more flexibility underneath.
FAQs
How do AI content detectors work?
They usually don’t compare your text to a “known AI database.” They score how predictable the writing is. Common signals include things like perplexity (how expected the next words are) and burstiness (how much sentence structure and length vary). More predictable text often gets flagged.
What’s a “false positive,” and why does it happen?
A false positive is when human-written text gets labeled as AI. It happens a lot with academic, highly technical, or very structured writing (including some non-native English writing), because those styles can look “too consistent” to a detector.
Can detectors catch text that a human paraphrased?
Depends on the detector. Simple tools may miss it if the wording changes. More advanced tools may still flag it if the structure and meaning stay very similar, because they look beyond exact phrasing.
How does LLM API fit into an app that also uses detection/moderation APIs?
Many apps use LLMs for generation (summaries, chat, drafting) and separate tools for detection/moderation. LLM API can simplify the LLM side by giving you one endpoint for multiple model providers, while you keep your detection API separate.
Does LLM API help with downtime for generative AI features?
Yes. If one provider is slow or down, LLM API can route requests to backup models through load balancing and fallbacks, so your app’s generative features are less likely to stall.